前端实现图片OCR: 选中、复制图片里文本
发布时间: 2024-12-19
为什么要复制图片文字?
有一个比较好用的产品,可能部分人使用过,TAPD ,一款敏捷项目管理工具,类似于禅道之类的在线应用,今天重点不是说项目管理工具, 今天主要是说说TAPD中有一项比较好用的功能,放大一张图片,可以直接复制图片中的文字,这个功能对于产品经理给出的需求,开发人员拿到里面的文案就非常好用。
现在企业微信、微信中已经具备这个功能了,但是对于Web来说,支持这个功能是更加复杂的,因为在Web中OCR天生就比较弱,node单线程,本身解释型语言性能也不算高。
既然TAPD已经有了,今天就来尝试动手写功能这个功能,所以有了此篇文章,最后我的demo我会放到github上,大家可以随意fork、测试。
运行图
本地OCR
本地使用Tessract.js识别文字,可以看到我们双击其中一处文字,上面输入框会显示我们选中的文字,可以用于测试对比识别效果。
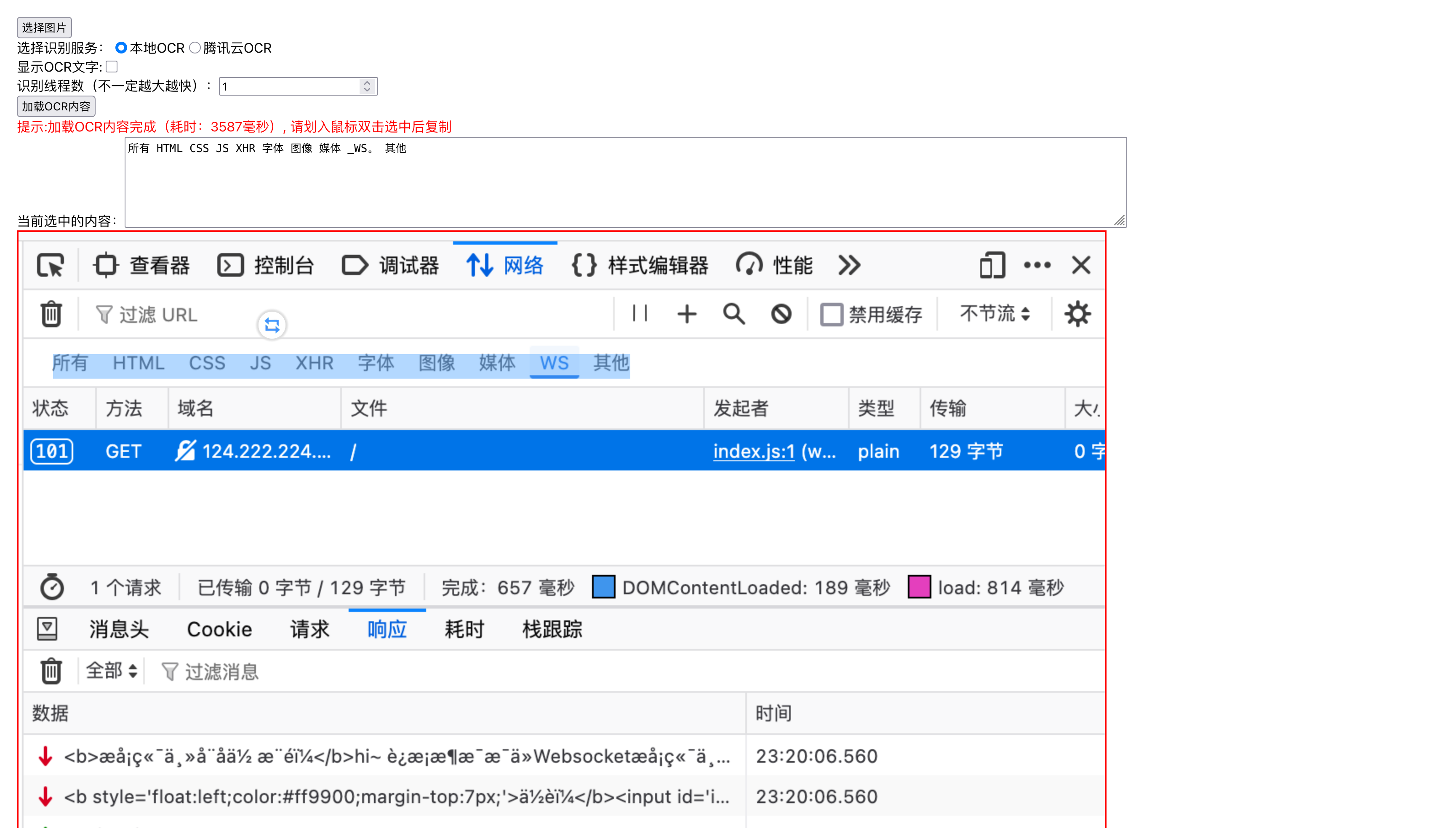
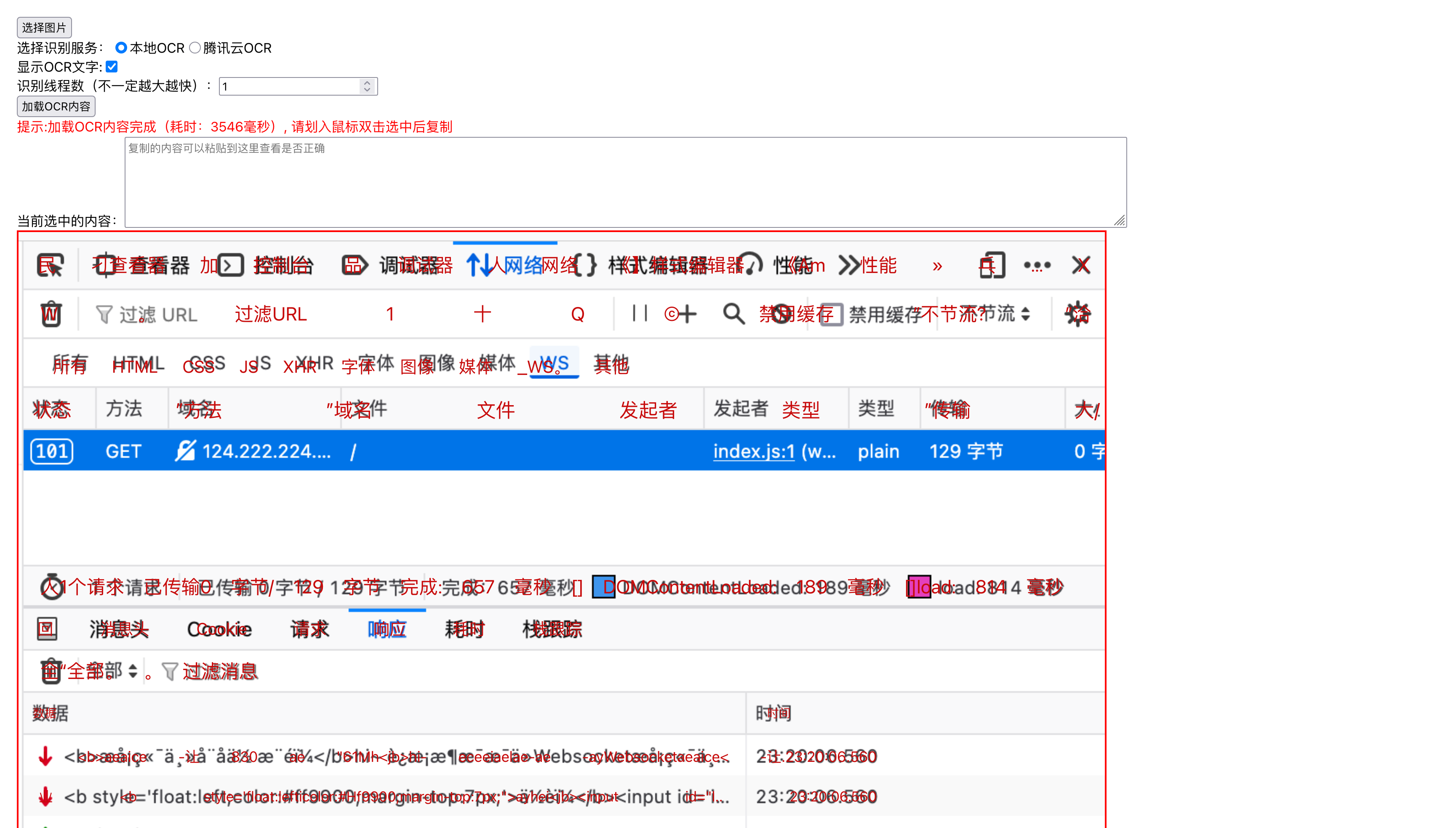
也可以打开文字显示,看看整体的识别、位置还原程度
腾讯云OCR
通过腾讯云OCR服务识别效果是明显好于本地Tessract.js的,双击其中一处文字,查看上面文本框
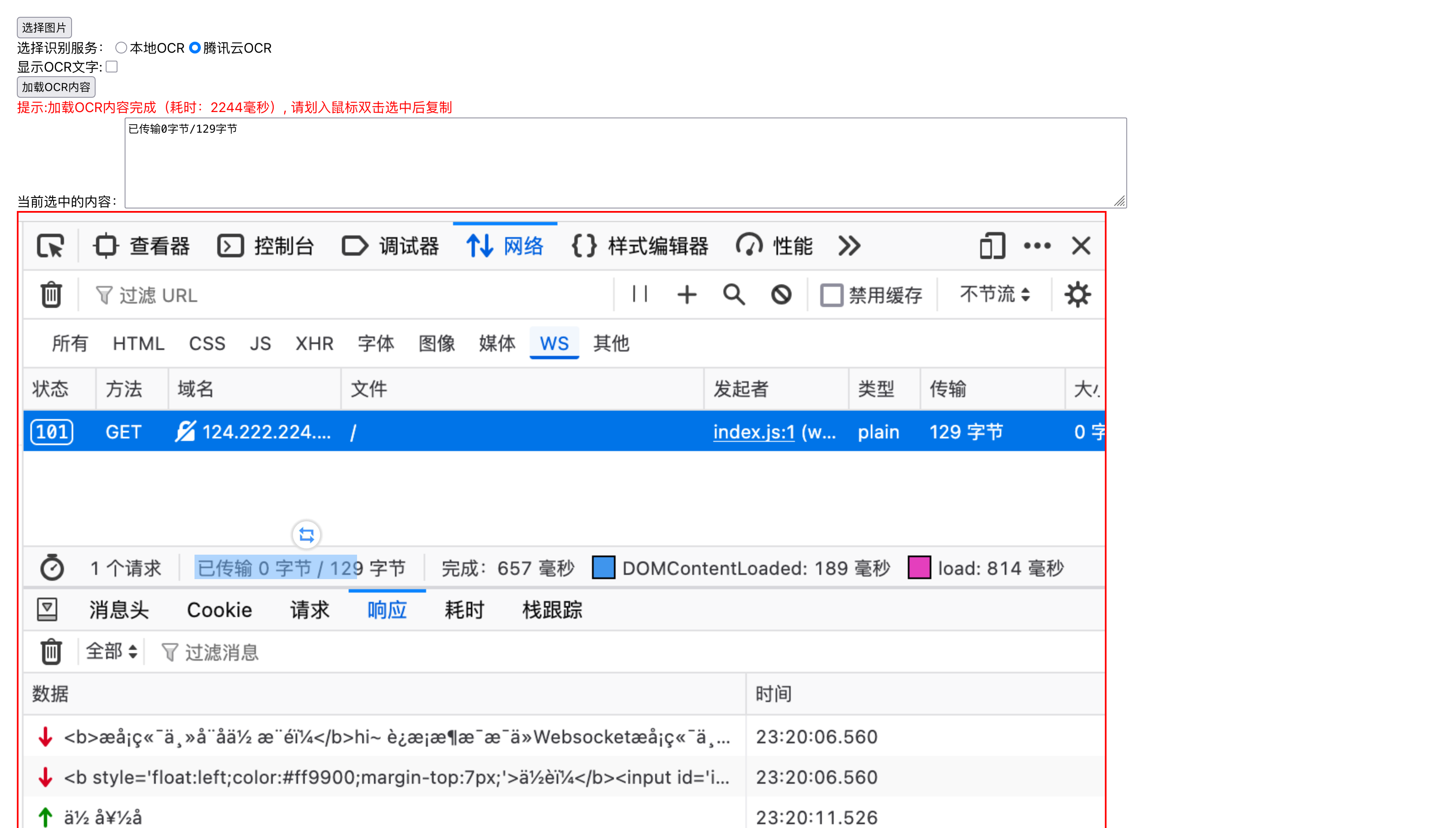
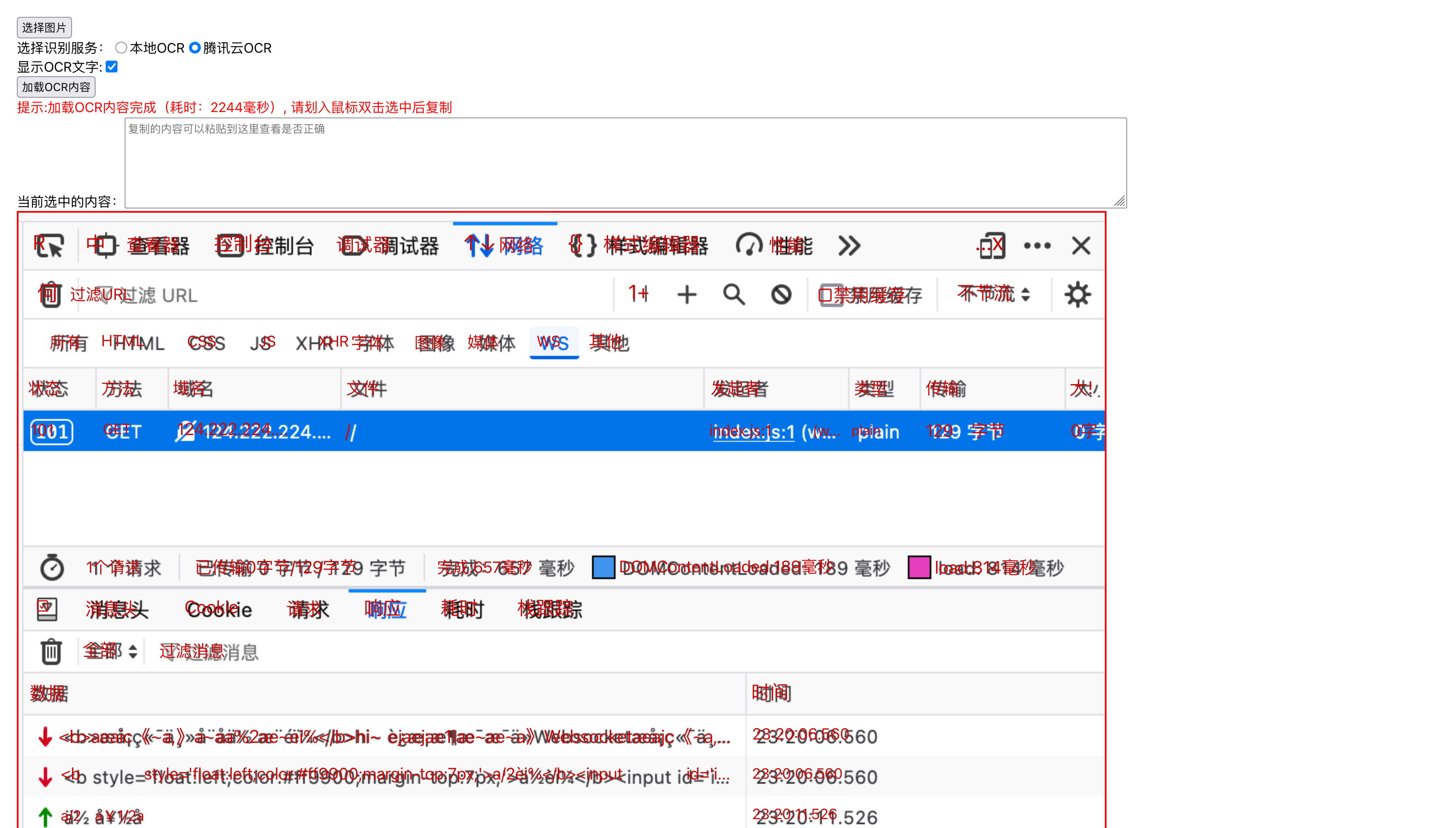
同样也可以打开文字显示,看看整体的识别、位置还原程度
实现思路
实现的思路很简单,分为两个部分
- 图片识别文字
- 前端在图片上对应位置放置文字
对于本地ocr来说,只需要使用tesseract.js识别图片即可,对于腾讯云来说,需要使用腾讯云的OCR服务,然后把识别结果返回给前端,前端再把识别结果展示出来。
本地ocr不论是从识别速度、准确率都是不如氪金腾讯云OCR的,还是那句话:加钱,世界触手可得!
为了更好的体验,我把tessract.js运行在服务端中,没有直接在react前端项目使用这个包,所以不论是本地、还是腾讯ocr都是通过我的node服务端来调用的。 他们的前端完全一样,有兴趣可以在最后的github地址中查看。
本地ocr
本地实现的逻辑是,拿到图片后,先做灰度化和二值化处理,然后交给tesseract.js识别文字,最后把识别结果返回给前端。
腾讯云ocr
逻辑就很简单了,直接http服务传入图片,拿到返回的识别结果。
最终返回前端的结果
格式如下:
export interface ConvertedItem {
// 文本
text: string;
// 左上角坐标
start: [number, number];
// 右下角坐标
end: [number, number];
}
const result:ConvertedItem[] = [{...},{...}];示例
{
"data": [
{
"text": "民 刁查看器 加 控制台 品 调试器 人 网络 《】样式编辑器 《Am 性能 » 乓 … X",
"start": [
22,
23
],
"end": [
1272,
55
]
},
{
"text": "W 。 过滤URL 1 十 Q © 禁用缓存 ”不节流? ”洽",
"start": [
26,
81
],
"end": [
1274,
113
]
},
...
{
"text": "炎 <b>ayaeaice< azas% doateivic/0>123123 23:20:27.627",
"start": [
24,
850
],
"end": [
1019,
875
]
}
]
}
前端拿到这些数据就可以把文字显示到对应的位置了。
核心代码实现
前端核心代码
前端就是依赖上面的数据结构,在把文字显示到对应的位置上:
<div className="image-container">
<img id="ocr-image" src={selectedImage!} alt="请先选择图片" />
{ocrResults.map((result, index) => {
const { text, start: leftTop, end: rightBottom } = result;
const height = rightBottom[1] - leftTop[1];
return (
<div key={index} className="ocr-text" style={{
color:`rgb(199, 10, 10${showOCRTxt?',1':',0'})`,
left: `${leftTop[0]}px`,
top: `${leftTop[1]}px`,
fontSize: `${height*0.7}px`,
width: `${rightBottom[0] - leftTop[0]}px`,
height: `${rightBottom[1] - leftTop[1]}px`
}}>
{text}
</div>
);
})}
</div>服务端核心代码
本地Tessract.js实现OCR
本地OCR最好将图片先预处理一下,二值化和灰度化,让图片更便于识别。
async function multiThreadOCR(imagePath: string, numThreads: number): Promise<ConvertedItem[] | undefined> {
const scheduler = createScheduler();
const workers: Worker[] = [];
try {
for (let i = 0; i < numThreads; i++) {
const worker = await createWorker("chi_sim+eng", OEM.DEFAULT, {
// logger: (m) => console.log(m)
});
worker.setParameters({
preserve_interword_spaces: '1'
});
scheduler.addWorker(worker);
workers.push(worker);
}
const res = await scheduler.addJob('recognize', imagePath, {}, {
hocr: true,
blocks: true,
layoutBlocks: true,
});
const { data: { lines } } = res;
const result: ConvertedItem[] = [];
lines.forEach((line: OcrLine) => {
const { text, bbox } = line;
const { x0, y0, x1, y1 } = bbox;
result.push({
text: text.replace('\n', ''),
start: [x0, y0],
end: [x1, y1]
});
});
return result;
} catch (error) {
console.error('识别过程中出现错误:', error);
} finally {
for (const worker of workers) {
await worker.terminate();
}
}
}
app.post('/ocr', async (req: express.Request, res: express.Response) => {
// 二值化和灰度化
const grayscaleResult = await binarizeImage(await grayscaleImage(req.body.image));
if (grayscaleResult) {
multiThreadOCR(grayscaleResult, req.body.threadNum).then((data) => {
if (data) {
res.json({
data
});
} else {
res.status(500).send('识别过程中出现错误');
}
}).catch(err => {
console.error(err);
res.status(500).send('识别过程中出现错误');
});
} else {
res.status(500).send('图像预处理出错');
}
});腾讯云OCR
腾讯云每个账号每个月都会给一些免费的OCR额度,如果用量不大的话,也是不需要自己花什么钱的。
const OcrClient = tencentcloud.ocr.v20181119.Client;
const clientConfig: ClientConfig = {
credential: {
secretId: process.env.secretId,
secretKey: process.env.secretKey,
},
region: "",
profile: {
httpProfile: {
endpoint: "ocr.tencentcloudapi.com",
},
},
};
app.post('/tencentocr', async (req: express.Request, res: express.Response) => {
const client = new OcrClient(clientConfig);
const params = {
"ImageBase64": req.body.image
};
client.GeneralAccurateOCR(params).then(
(data) => {
res.json({
// 把腾讯云返回的数据结构转换成和我们本地OCR一样的结构
data: convertData(data)
});
},
(err) => {
console.error("error", err);
res.status(500).send('识别过程中出现错误');
}
);
});存在的问题
不管是本地识别还是腾讯云识别,因为不是个性化场景打磨的识别算法,所以可定制化程度几乎没有,这也就无可避免的出现识别效果可能不是很友好,存在如下比较麻烦的问题:
- 本地OCR文字识别率有些许问题,用的tesseract.js
- 文字在图片上为的位置还原有问题,主要是识别文字字号及中间空白的宽度困难
Demo可以优化的点
- 建立一个标准,对图片从大小、分辨率来划分界限,小图片可以使用本地OCR速度很快1秒多出结果,大一些的走腾讯云
- 优化文字在图片上的还原,尽可能保持重叠。
- 本地ocr可以研究tessract的words数据,本demo用的是lines数据,相对来说words数据粒度更细。也可以看看hocr的输出,是否还原效果会更好。
- 对于图片组件的封装,完全复刻Tapd的图片缩放、拖拽,并保持OCR数据。
项目地址
本文所用Demo项目源码地址:https://github.com/gtjyj/img-ocr-text-copy
欢迎大家查看源码,fork修改。
